
Table of contents
- Structured vs. unstructured data: A quick overview
- What is structured data?
- What is unstructured data?
- Side-by-side comparison of structured vs. unstructured data
- What is semi-structured data?
- Best practices for protecting structured and unstructured data
- How Code42 Incydr can help with structured and unstructured data
Organizations are collecting ever-increasing amounts of structured, unstructured, and semi-structured data in the modern data landscape. According to MIT, unstructured data represents 80–90% of companies’ data collection. As the proportion of an organization’s unstructured data grows, protecting that data becomes increasingly complex, especially with traditional Data Loss Prevention (DLP) tools.
Data in isolation does not pose a risk, necessarily. But aggregate data with context creates digital footprints that illuminate trends and patterns malicious actors can use to their benefit. Because of this, predicting which data – structured or unstructured – could cause the most damage is impossible. The nature of unstructured data makes it especially difficult to assess for risk. As unstructured data continues to grow and become more common, ignoring the problem is simply not an option.
Continue reading to learn the differences between structured and unstructured data with tips on protecting all data types.
Structured vs. unstructured data: A quick overview
In short, structured data is quantitative, formatted data stored within a fixed schema, while unstructured data is qualitative, unprocessed data stored in its native format. While structured data can come in text and numeric values, like names, addresses, and phone numbers, unstructured data doesn’t have to fit into a fixed record with rigid schema rules. Therefore it is more likely to be rich media, video, audio, or large text files that don’t conform well to tables and columns. The differences between structured and unstructured data become clearer through comparison, which we’ll discuss later.
What is structured data?
Structured data is information that adheres to a standard, fixed format. Structured data consists of set data types inside a defined schema, typically within a relational database management system (RDBMS) like MySQL, PostgreSQL, or Microsoft SQL Server. Large amounts of structured data from multiple data stores, like your organization’s application and Salesforce instance, can reside within a data warehouse.
Pros of structured data
Structured data remains a necessary way to collect and store data because of several advantages:
- Structured data is easy to use and analyze because users know what questions they can ask of it and have clear expectations of how the database will respond.
- Structured data is more straightforward to share with non-technical users, facilitating data democratization. With SQL and the many business intelligence tools built on top of it, non-developers can visualize and analyze structured data with minimal technical assistance.
- Setting up, collecting, and storing structured databases is relatively easy and inexpensive, with a variety of RDBMS available. For example, spinning up a SQLite instance requires minimal time, cost, and technical know-how.
Cons of structured data
Despite some clear benefits, using structured data can also bring some challenges:
- Making changes to the schema later on can come with significant overhead, requiring time-intensive impact analysis and risky migrations.
- Attempting to store data that fits the schema is possible, but the data must undergo a transformation, or the schema must change to accept the data.
- Structured data modeling works well when representing straightforward information, but it often can’t capture the complexity of real-world relationships. For example, structured data is great for storing the basic contract information between an organization and its clients, but it may not accurately describe the many types of interactions and communications between the organization, the client, and its products.
What is unstructured data?
Unstructured data is information stored in its native format and has no enforcement to organize it. Unstructured data is easy to collect and store without meeting a predefined format. On the one hand, not having to enforce a schema makes storing information much simpler, especially data that doesn’t translate easily into text and numbers, like video and audio files. On the other hand, unstructured data is difficult to search, filter, or combine with other datasets without this strict formatting.
Pros of unstructured data
Unstructured data is becoming increasingly popular thanks to its positive qualities.
- Unstructured data allows quick and easy storage because there is no need to treat the data to match a schema. Organizations don’t need to invest time and effort in creating a schema and writing methods to transform data to fit the schema.
- Saving information in its raw format is relatively cheap. Especially with cloud storage, organizations don’t need to make significant investments to begin collecting and storing unstructured data. Storing unstructured data can be as quick as configuring an s3 bucket.
- Unstructured data often includes information that may be useful later but may not have a straightforward application in the present moment. However, you can always decide how to process and analyze it later.
Cons of unstructured data
Even with unstructured data’s inexpensive collection and storage, associated costs can quickly increase.
- While easy to store, unstructured data requires expertise to analyze. Typically, data scientists must use sophisticated methods like natural language processing.
- Unstructured data is inexpensive to store but expensive to process. The more unstructured data your organization collects, the more computational power you’ll need to process the data before it’s available to analyze.
- Unstructured data can house sensitive or confidential data without a clear way to identify, classify, and tag those files. Compliance with regulations like GDPR can become more complicated when organizations need help finding all the instances where sensitive data lives.
Side-by-side comparison of structured vs. unstructured data
This table gives an at-a-glance summary of the differences between structured and unstructured data:
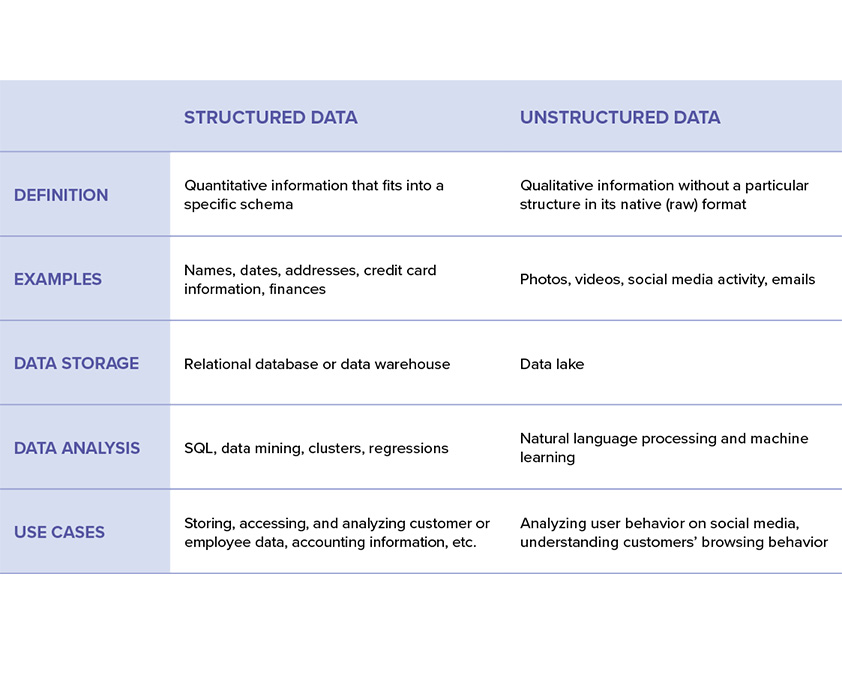
What is semi-structured data?
Semi-structured data incorporates some aspects of structured data that make it organized, searchable, and analyzable but lacks the strict rules of structured data. As the name implies, semi-structured data sits between structured and unstructured data. Semi-structured data can include organization within a file or document, but storage doesn’t enforce a schema.
Because it incorporates elements of structured and unstructured data, semi-structured data can appear within a structured data record through a format like XML or a JSON blob. These records are still searchable via SQL but require more advanced syntax to query. Alongside modified RDBMS, semi-structured data can also live within NoSQL databases like MongoDB.
Best practices for protecting structured and unstructured data
Now that we’ve examined the differences between these two data types, let’s look at the best ways to protect both. Identifying and classifying structured data is relatively straightforward. You can apply access controls on top of any sensitive data and monitor if anyone moves, shares, or modifies the data.
Unstructured data, on the other hand, is harder to protect. Sensitive data might be hiding within the native, unsearchable format of these files, and a computer program will have more difficulty searching, flagging, and tagging any instance of personally identifiable information (PII) or other types of sensitive data. Finding sensitive data within these kinds of audio, video, or large text files takes more computing resources and, in general, is more expensive. Here are six tips for protecting sensitive data.
Rather than relying on the traditional flagging and monitoring methods common with structured data, a better practice is for an organization to monitor all data changes and movement across both types. If any modifications or sharing seems suspicious, you can investigate to determine if the activity results from malicious behavior.
Fortunately, more and more applications are rising to meet this challenge. Artificial and business intelligence tools can track all data’s movement and modifications. By watching all data movement, security teams can identify potentially harmful actions before a leak becomes a breach. This approach also brings more nuance to your organization’s security practices beyond basic access controls, which can frustrate users and push them to work around any safeguards.
How Code42 Incydr can help with structured and unstructured data
Organizations are collecting and storing an ever-expanding amount of unstructured data. As organizations gather more and more unstructured data, it will become increasingly difficult to adequately secure and monitor.
While the conventional methods of DLP may work well with structured data, a changing data landscape calls for new tools. Code42’s Incydr takes an updated approach by observing all structured and unstructured data movement, regardless of classification. Incydr moves beyond pre-identifying and outright blocking all data exfiltration. Instead, it uses context to detect suspicious actions, automatically prioritizes risky activity to cut through alert noise, and contains leaks before major damage is done.
